

Making Useful Language Models
How do we make language models that users want?


Back in the 1950s, the world was recovering from global war and ramping up investments in science and technology. Nuclear technology development marched forward with the Hydrogen bomb and the first commercial nuclear power plants. The Space Race was heating up between the US and the Soviet Union, leading to the founding of NASA. Jonas Salk developed the polio vaccine and its mass production helped millions across the world. The computer age was also in its nascency; the UNIVAC I ushered in the age of general-purpose computers, soon followed by the IBM 701 and 650.
And up in the bucolic hills of the Hudson Valley, Arthur Samuel was teaching a computer to play checkers.
Programs that played checkers existed then, but Samuel wanted his to be the best. One way to be the best at a game is to “solve” it — examine every possible outcome and find every winning move. By mapping out every possibility, your program can have a winning strategy for every situation.
But it wasn’t possible for Samuel to solve checkers with the computers available to him. A game of checkers can have over 500 quintillion possible combinations of moves (or 500 billion billions). He would die before a tiny fraction of moves were found.
Samuel realized that he didn’t need to solve checkers for his program to be the best. He needed a program that could learn to eventually beat the best programs and players.
So here’s what he did: for a given arrangement of pieces, his program would explore a set of possible next moves. Because it wasn’t feasible to search every possible move and outcome, Samuel developed a way to score moves based on the chance of winning after the move was played. He realized that his chance of winning was correlated with how many more pieces he had than his opponent. So his program tried to hold onto as many pieces as possible.
Samuel added another crucial piece: memory. The program could remember every board it had seen before along with the final scores, allowing it to efficiently search additional moves for potential wins.
In later versions of the program, the program’s scoring system was tuned based on the results of real professional games and having the program play itself thousands of times. Each new experience created new knowledge for the program.

In 1956, Samuel’s program was demoed on TV. IBM, where Samuel worked, organized a demonstration for their shareholders. Their stock price rose by 15 points in a single day.
In 1959, Samuel published a paper called “Some Studies in Machine Learning Using the Game of Checkers” in the IBM Journal, popularizing a phrase that would eventually launch a million startups.
In 1962, the “self-proclaimed checkers master” Robert Nealey went toe-to-toe with Samuel’s Checkers program — and lost.
In 2007, “Checkers is Solved” was published in Science: a large team managing dozens of computers ran over 1014 calculations — 1000 times the number of stars in the Milky Way galaxy — to create the perfect checkers program. They began in 1989, the year before Arthur Samuel passed away.
How do machines learn to win when the winning move is unknowable?
At the heart of Samuel’s checkers program are a few key ideas:
Machines can improve when given more data.
We can use functions to gauge a machine’s performance.
Machines can exploit their knowledge or past experiences to make better decisions.
If we allow machines to explore different possibilities, they could find optimal solutions even when a definitive solution is unknowable.
Samuel’s program was an early example of something we now call “reinforcement learning” or RL. Reinforcement learning is a field of machine learning where we treat our algorithm as an agent interacting with an environment.
The goal of RL is to teach the agent to navigate its environment effectively. Environments can be physical (like a house) or digital (like a Starcraft map). They can even be abstract, like a mathematical representation of a library of poems.
Navigating complex environments can require complex strategies. And developing a great strategy takes time, experience, and experimentation.
We know this intuitively; whether it’s outwitting your friends at Settlers of Catan or becoming great at ping pong, it takes practice. And if you’re a parent, you can appreciate how much chaos goes into teaching your kid the basics of staying alive, let alone thriving. Exploring what’s possible and examining the effects of our actions is fundamental to how we learn and grow.
In RL, to help an agent learn we encourage it to explore. We then give it feedback on what it’s doing. Like a parent letting its baby crawl around the house but shooing it away from a glass coffee table, we allow the agent to explore different actions, then we reward them for ones we want to encourage and penalize them for ones we want to discourage.

Over time, agents (and most children) learn to take actions that lead to more rewards, and align their behavior to their incentives. As model developers (and parents), we hope that the strategies they’ve learned help them navigate changes to their environment and new environments entirely.
Samuel and his contemporaries’ work continue to influence how we teach machines how to navigate complex, uncertain, and open environments. You’re already benefiting from reinforcement learning in your day-to-day life. You’ve interacted with reinforcement learning models when playing your favorite video game, when you shop online, when you get a package from Amazon, and even when you schedule nurse shifts at the hospital.
Teaching models to do useful things with text
Human language is also a complex, nuanced environment, and reinforcement learning has been a significant contributor to the recent boom in language modeling.
To understand how, let’s first take a look back at how modern language models were developed.
In 2017, researchers at Google and University of Toronto published “Attention is All You Need,” which introduced the “transformer” model architecture. The transformer boasted several improvements over prior model architectures. Notably, transformers can be trained faster and more efficiently, and can handle context better.
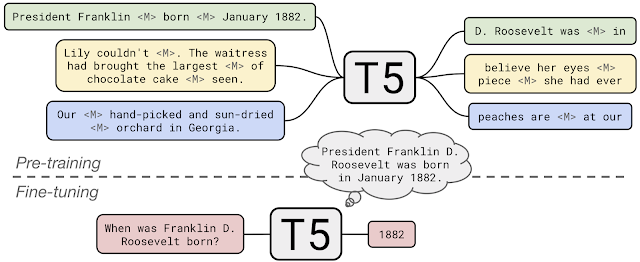
In 2018, the BERT (Google) and GPT (OpenAI) papers brought the transformer into the limelight. These papers demonstrate that we could model language with surprisingly simple approaches. For BERT, the model is given a corpus of text. However, some words are missing (or “masked”) and the model is tasked with filling in the blanks. For GPT, the model is shown the first part of a sentence or paragraph and asked to predict the next word. Neither approach requires labeled data, so these new transformer models can process lots of unstructured, unlabeled text.
Filling in the blank and auto-completing sentences are useful tasks, but we also want our language models to do other things, like answering questions or summarizing documents. These papers demonstrated that the information the models learned from their baseline tasks could be transferred to new tasks (a concept very cleverly referred to as “transfer learning”). The researchers added new layers to the models and fine-tuned those layers using labeled data to help the models perform new tasks. For example, a developer could take a baseline BERT model, add more neurons to it, and fine-tune them to predict the sentiment of a message or to answer questions.
The process of learning from unlabeled data is now commonly referred to as “unsupervised pre-training” (USPT), while the additional step of adding layers to the model and training them using labeled data is often called “supervised fine-tuning” (SFT).
The two-pronged approach of unsupervised pre-training and supervised fine-tuning is very powerful. During unsupervised learning, the model can learn a vast number of statistical relationships between words. Some researchers suggest that pre-training helps language models understand the basic rules of language, which used to require more complex pipelines. Supervised learning then helps the model do something with what it’s learned.
A drawback to multi-tasking with earlier models is it requires multiple models or adding multiple task layers to one model, each of which can increase the complexity of development and deployment.
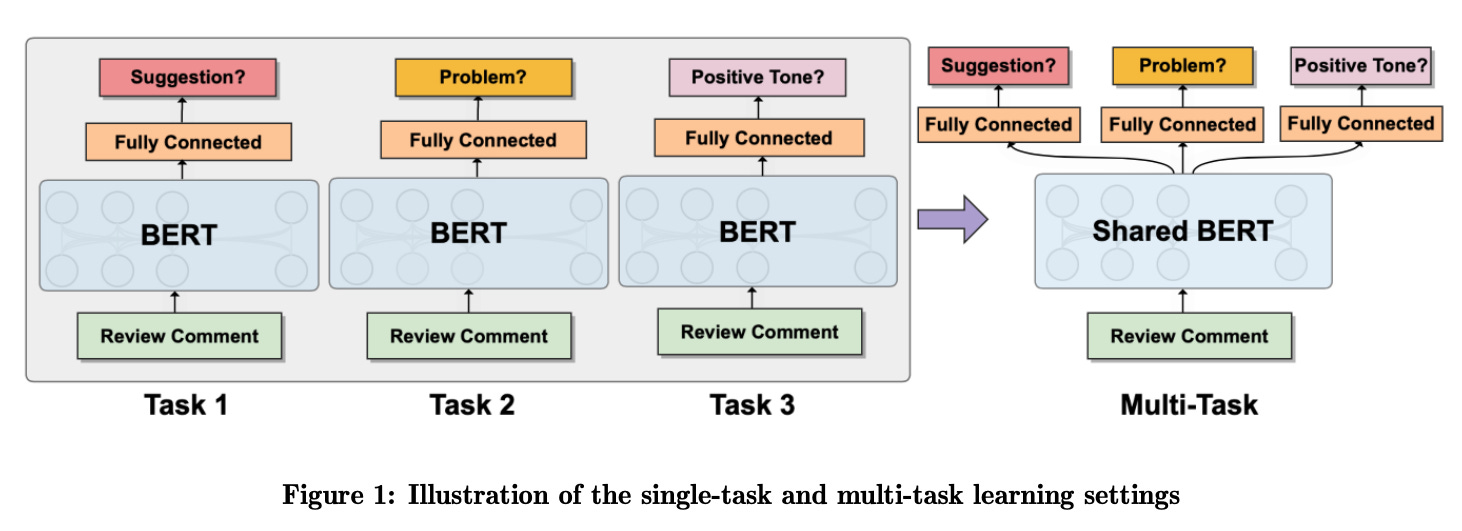
However, researchers soon found that we could train transformers to multitask more flexibly, without task-specific architectures.
For example, in 2019, researchers at Google created the T5 model. T5 can perform multiple tasks by framing each task as a “text-to-text” problem — every input and the expected output is just a string of words.1 The developers pre-fixed each input with a phrase that indicates which task T5 should perform, like summarizing a document (“summarize:”) or translating text between languages (“translate English to German:”). The model then learns to generate the expected output.
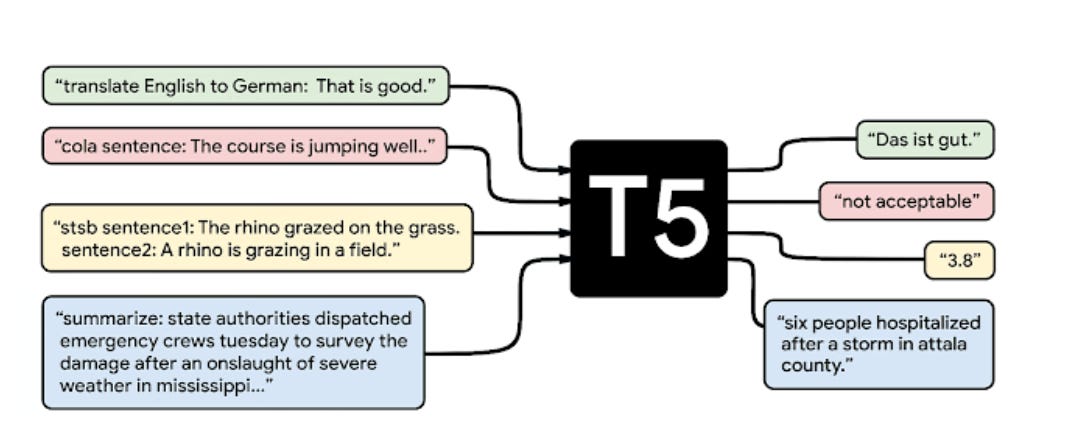
T5 is pre-trained in a similar way to BERT. But during supervised fine-tuning, was provided example prompts and expected responses2:
Alignment, or teaching models to do what users want
Users expect that language models should do what they ask, do them well, and do them to the user’s own tastes and preferences.
Sadly, supervised fine-tuning is not enough at meeting users’ expectations.
Why not? Supervised fine-tuning teaches models to give an expected output for a given input. However, this approach has the same drawbacks of any supervised learning algorithm: what if the training data doesn’t look like real world data?
If a new user’s requests aren’t similar to the instructions the model was trained on, will the model understand them? Will its prior training help it understand what the user wants? Will its output even be correct?
Pragmatically, we can’t train a model how to function in every possible context or use case. Like Arthur Samuel’s checkers program, the number of possible “moves” — or users and prompts — is too large.
Instead, models need an understanding of what users want. They need a way to judge which responses might align with user expectations, even when the user prompts are not seen in the training data.
In recent years, reinforcement learning has emerged as a powerful way to align models to user preferences. To get a sense of where the field has come and where it’s going, let’s look at the reinforcement learning technique that greatly improved the capabilities of large language models like GPT 3.5 and 4, as well as emerging optimization techniques.
Reinforcement Learning with Proximal-Policy Optimization (PPO)
In 2017, researchers at OpenAI published a paper on Proximal Policy Optimization, or PPO, a reinforcement learning technique I’ve come to call “eh, this is good enough.”
Reinforcement learning can be an unstable process. Sometimes models might make large changes to how they behave from a new reward signal. That can cause them to unlearn good behaviors, or become erratic.
The authors of PPO had a critical insight — when a model is getting effective results, the changes to its policy should be very minor. This can help stabilize how the model learns.

In PPO, we prompt a language model but, unlike supervised fine-tuning, we don’t provide an acceptable response. Instead, the model generates a response and a separate reward model (RM) gives it a score, indicating whether the response was acceptable. The language model's new objective is to produce responses that score highly.
In the literature, a reward model is often called a Preference Model (PM) because its goal is to predict which responses users will like. To train an RM/PM, we create a comparison dataset, consisting of prompts and different possible responses. Two responses are compared and one is labeled as “preferred.”
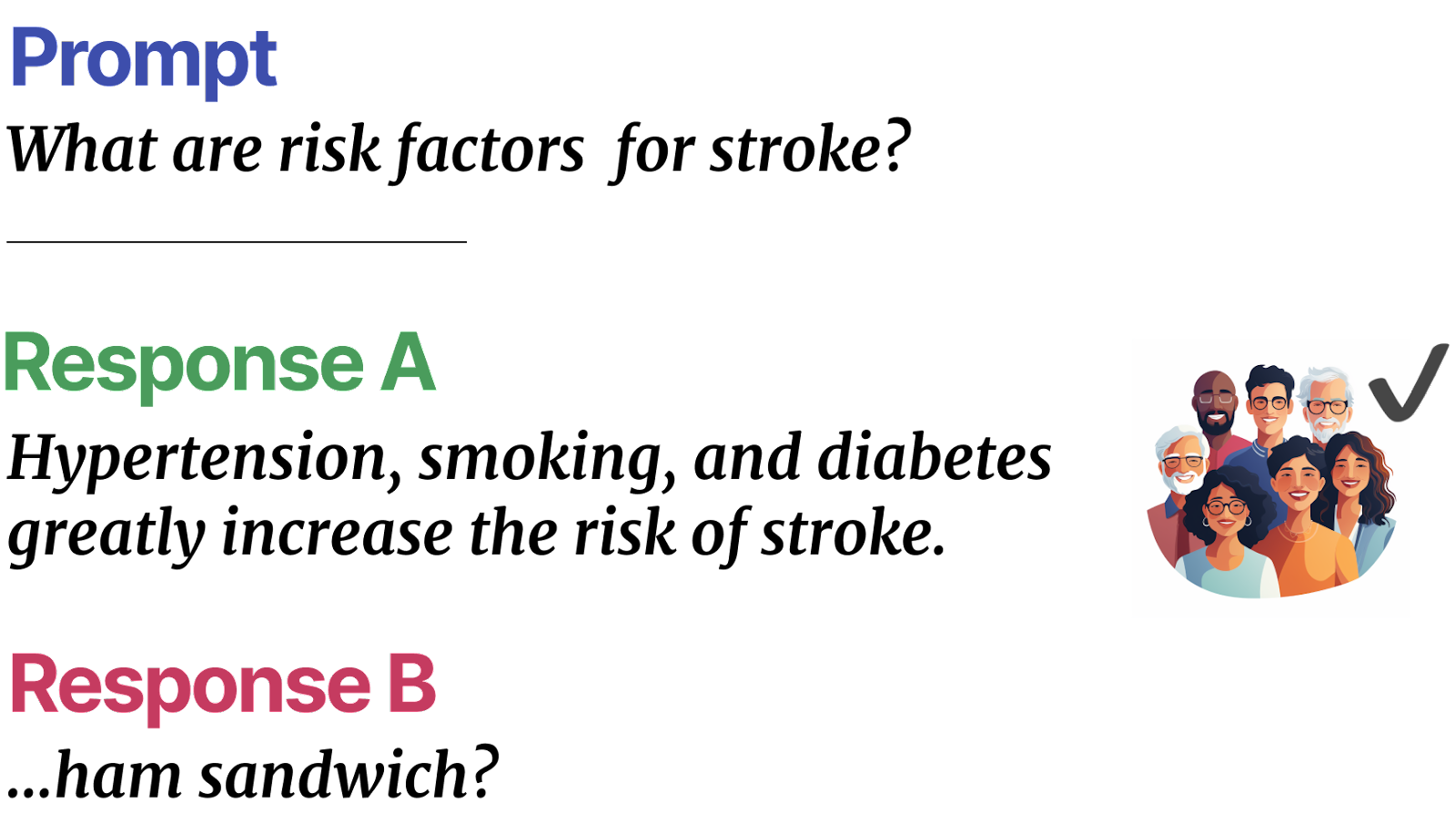
Using comparison data, a reward model is trained to predict preferred responses and produce a score that reflects how likely a user is going to prefer a response. The signal from the reward model is then used to fine-tune the model on better prompts and responses.
The scores are what give our language models an important signal: how much do you think a user will like this response? Comparison data should be designed to reflect user preferences and desired behaviors (like should responses be short or verbose, professional or snarky, toxic or courteous?). Then the reward model can act as a proxy for the user.
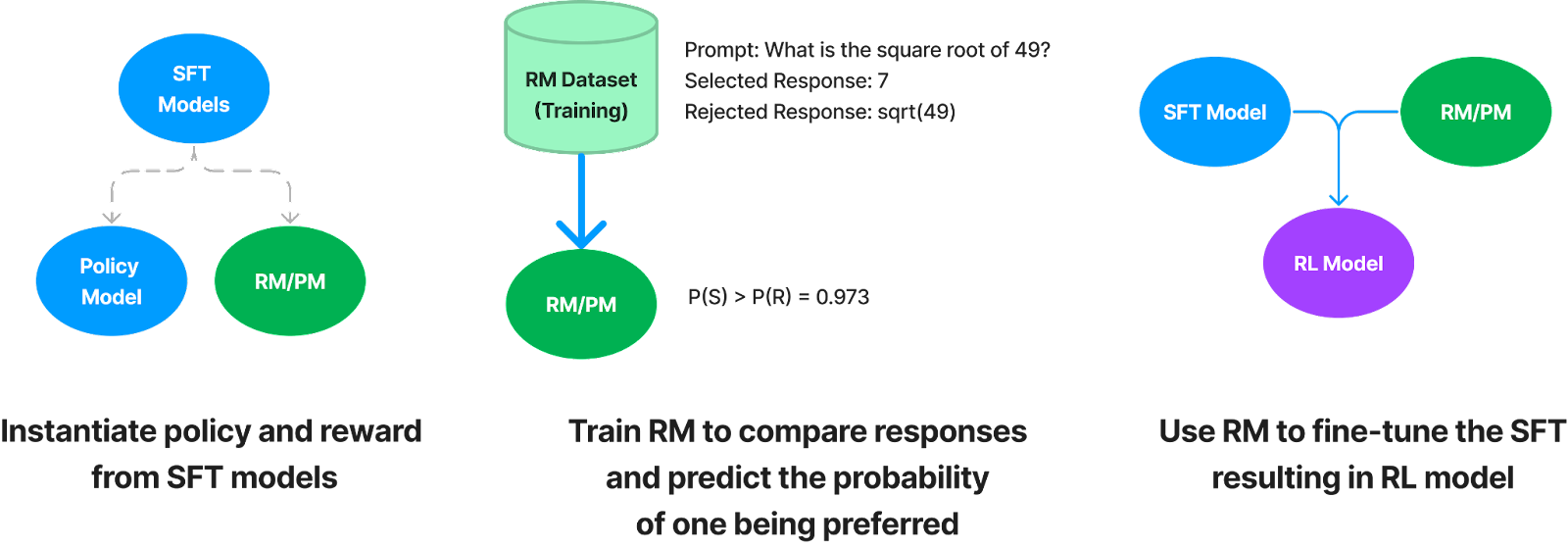
Reward modeling is also useful because it can help compare different models or systems. Let’s say you’ve trained a reward model to accurately predict the preferences of nurses in your clinic. You’ve also created a library of prompts that reflect tasks that are important to them. When developing models or benchmarking new open source models, you can compare the reward scores for each model, to determine which one will serve the nurses best.
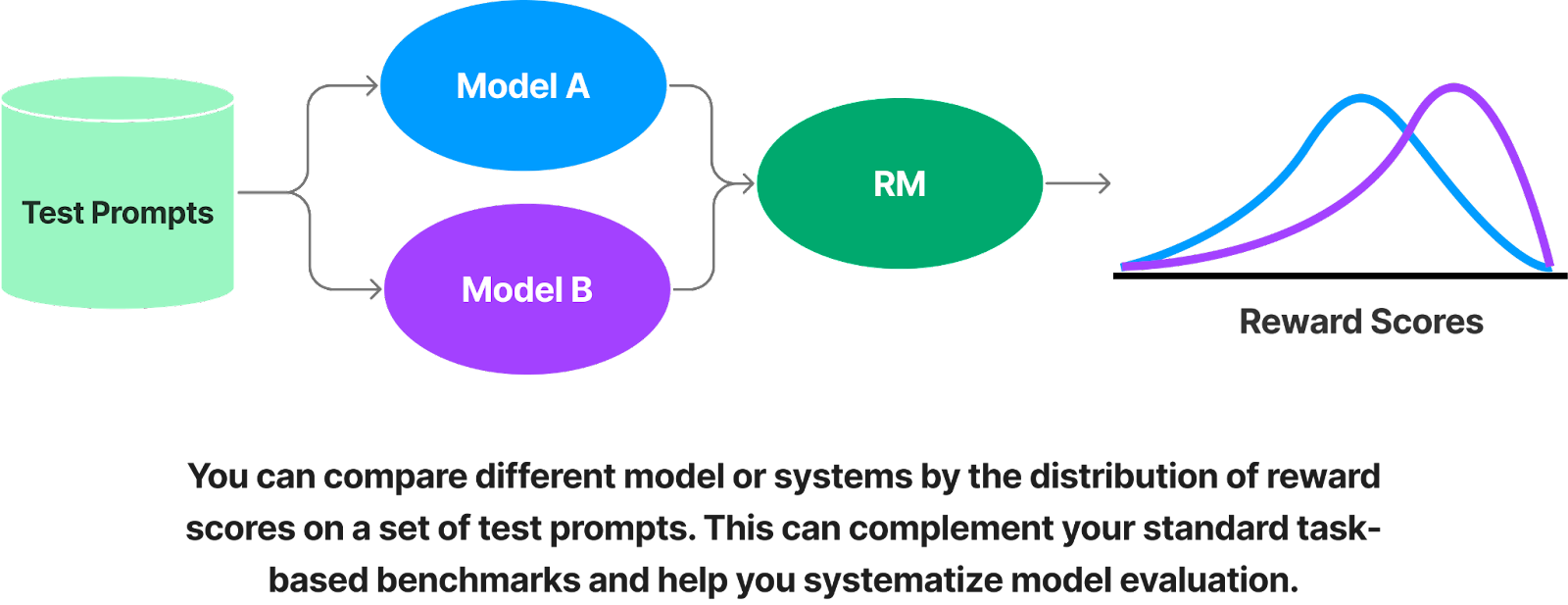
PPO was first applied to language models to improve text summarization. Using a dataset of Reddit posts with “TL;DRs” (author-generated summaries of the post), researchers trained a set of language models to summarize text. They asked people to compare machine-generated summaries to the original summaries. When the summary was generated by a pre-trained or fine-tuned model, the reviewers preferred the human summary more often. But a model trained using reinforcement learning with human feedback (RLHF-PPO) generated responses that were preferred over the original summaries, even when the model was relatively small (1.3B parameters):
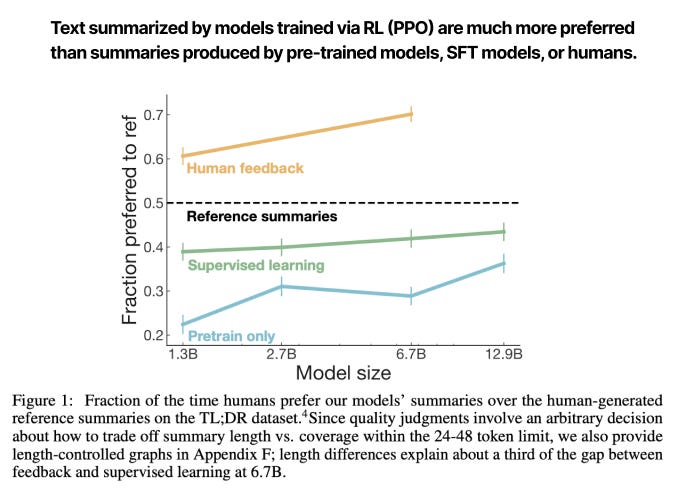
In 2021, OpenAI researchers then applied this technique to GPT-3. In this case, GPT-3 was trained to perform a wide range of tasks, not just summarization. Could RL via PPO generalize to other tasks? The authors compared a supervised fine-tuned 175B-parameter GPT-3 model to models trained using PPO, both big (175B params) and small (1.3B).
The results were compelling: a 1.3B parameter model trained with reinforcement learning was on par, perhaps slightly better, than a 175B parameter model that was only fine-tuned, even though it was two orders of magnitude larger. Technique, not size, won the day.
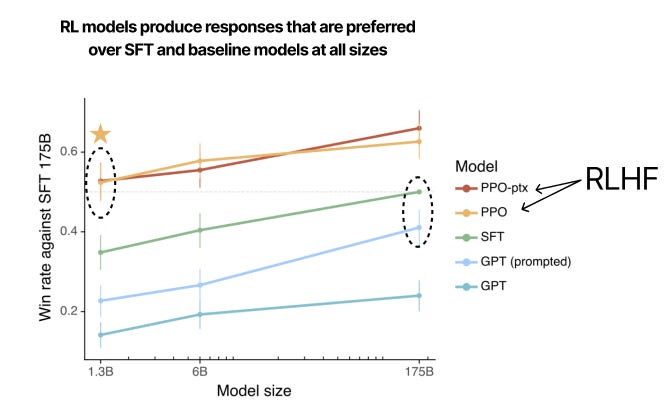
Interestingly, the compute resources needed for RL are much less than the cost of pre-training. For the 175B parameter GPT-3 model:
It took 3640 pFlops/s-days to perform unsupervised pre-training (USPT)
Only 4.9 pFlops/s-days for SFT (0.13% of USPT)
And 60 pFlops/s-days for PPO (1.64% of USPT)
In 2023, researchers at Meta’s Llama 2 model had better performance with RL-PPO than fine-tuning alone. Successive rounds of RL improved model performance significantly.
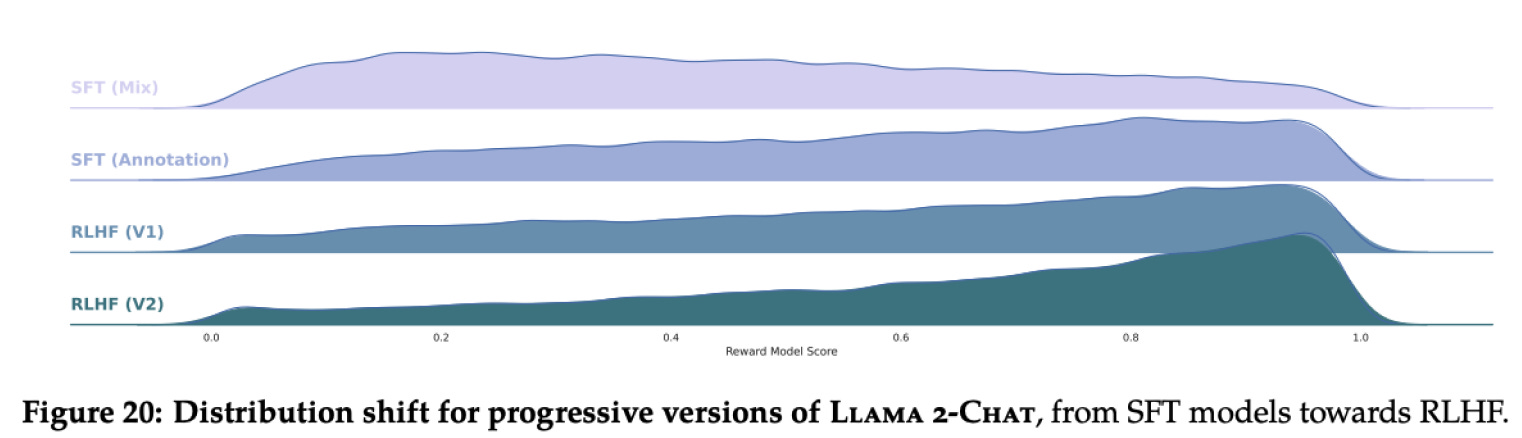
RL via PPO has been shown to be incredibly powerful. However, it does have limitations; RL can be complex to setup, gathering data can be challenging, and training can be unstable even with the benefits of PPO.
Recently, some researchers have tried to simplify the alignment process by refining how models learn from preference data. These new methods still use user preferences, but with some twists. Let’s dig into two recently published methods: Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO).
Direct Preference Optimization (DPO)
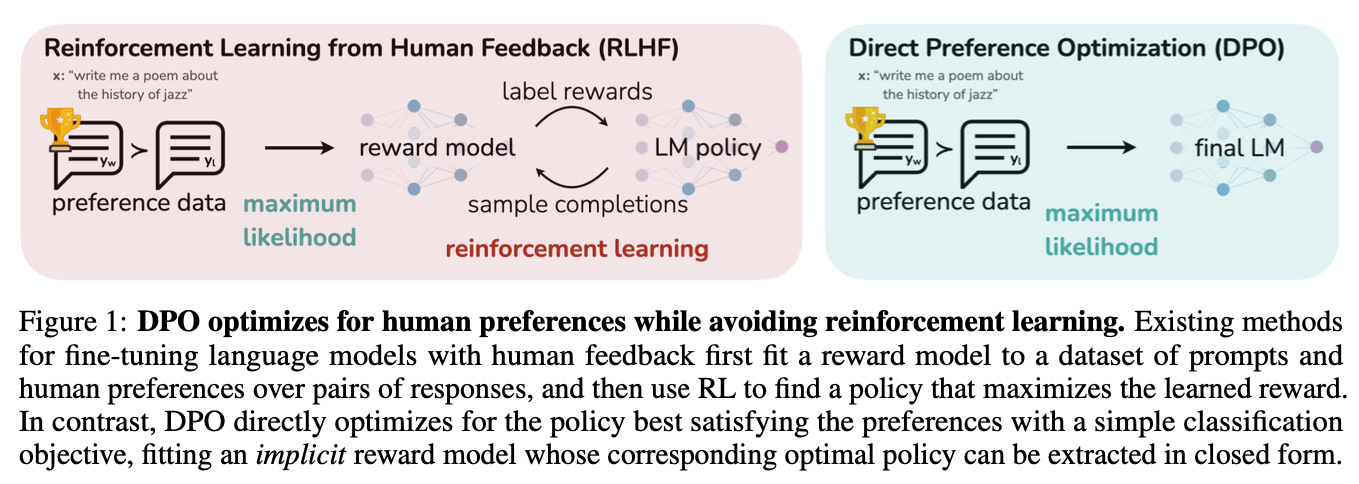
Last year, researchers from Stanford proposed a new method for aligning language models to human preferences, called Direct Preference Optimization (DPO)3.
During PPO, we maintain a separate reward model that predicts human preferences, then use RL to optimize a language model to maximize the reward. The authors of DPO argue that this workflow is complex and computationally expensive.
Instead, they propose that the language network itself can implicitly represent a reward model. The authors optimize the model directly using a simple binary classification loss.
The authors’ performed experiments on sentiment control, summarization, and dialogue. They found that DPO models perform as good or better than PPO models trained. At most model temperatures4, DPO matches or beats all other techniques, including picking the best of 128 possible responses.
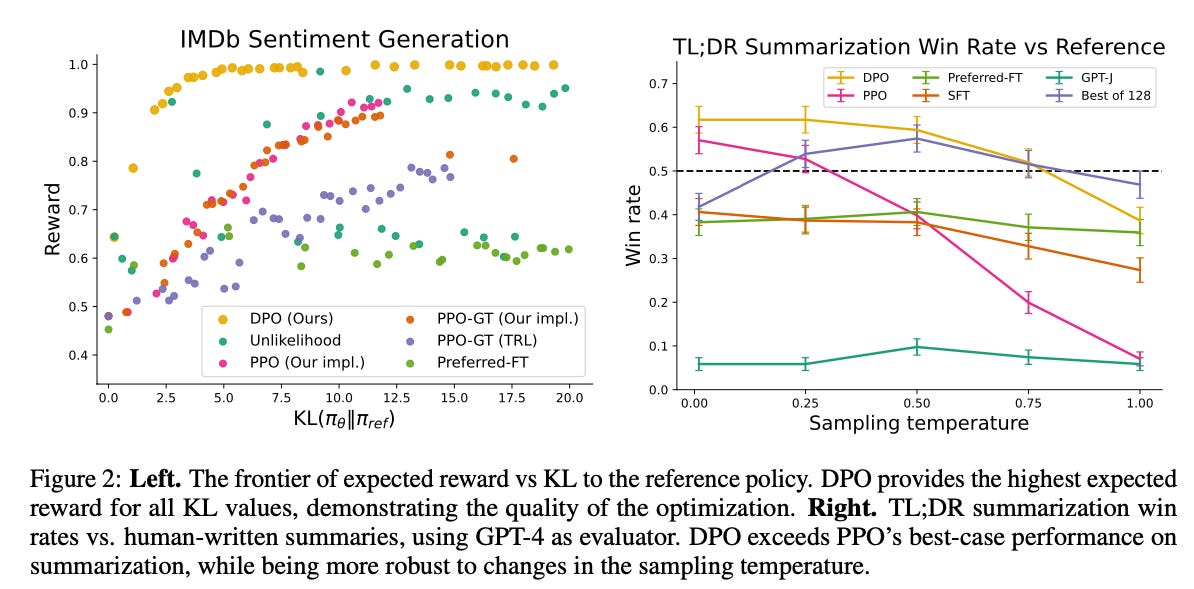
We’re still understanding how well DPO generalizes to other model sizes, tasks, and domains. If it does, DPO could provide a simpler, more stable, and more lightweight approach to alignment, addressing common challenges in applying RL-PPO at scale, while still giving users the ability to provide direct feedback to how language models behave.
As a field, we often start with complex methods, then refine them down to the essentials, and finally conclude that “XYZ is all you need.”
Kahneman-Tversky Optimization (KTO)
DPO and PPO-based reinforcement learning focus on quantifying how well language models’ responses align with human preferences. For both, the model is presented with a prompt and two possible responses, and is asked to choose which response a user would prefer and produce a score.
Recently, a new paper from ContextualAI proposes a human-centered loss-function (HALO) with Kahneman-Tversky Optimization (KTO), which is based on prospect theory.
Prospect theory seeks to explain how people make (often irrational) decisions in uncertain situations, especially concerning money.5
When we make decisions that carry risk or uncertainty, we think about potential wins and losses compared to our internal reference point, rather than just the absolute numbers. We also tend to really hate losses (losing $1000 makes us feel much worse than winning $1000 makes us feel good). So when weighing uncertain outcomes, we put extra emphasis on the small chance something really bad could happen, compared to the value of likely good outcomes. In other words, people are “loss-averse,” we worry strongly about bad outcomes more than we celebrate positive ones.
So what does this have to do with language modeling? KTO tries to account for similar human biases that may appear in the preference data.
Users tend to have relative expectations about whether a language will be helpful, and will narrow in on a few bad responses rather than appreciating when the model is generally good. So KTO makes the model judge its own responses like people do, each response is compared to how helpful responses usually are and tries to avoid bad responses more than it seeks great ones. Basically, by modeling biased human judgments, KTO teaches models to avoid our pet peeves.
In practice, this simplifies preference learning. The model only needs to know if outputs are desirable or undesirable. It doesn’t need a full comparison dataset. So instead of learning preferences, the model shifts to learning how useful or unwanted a response is.
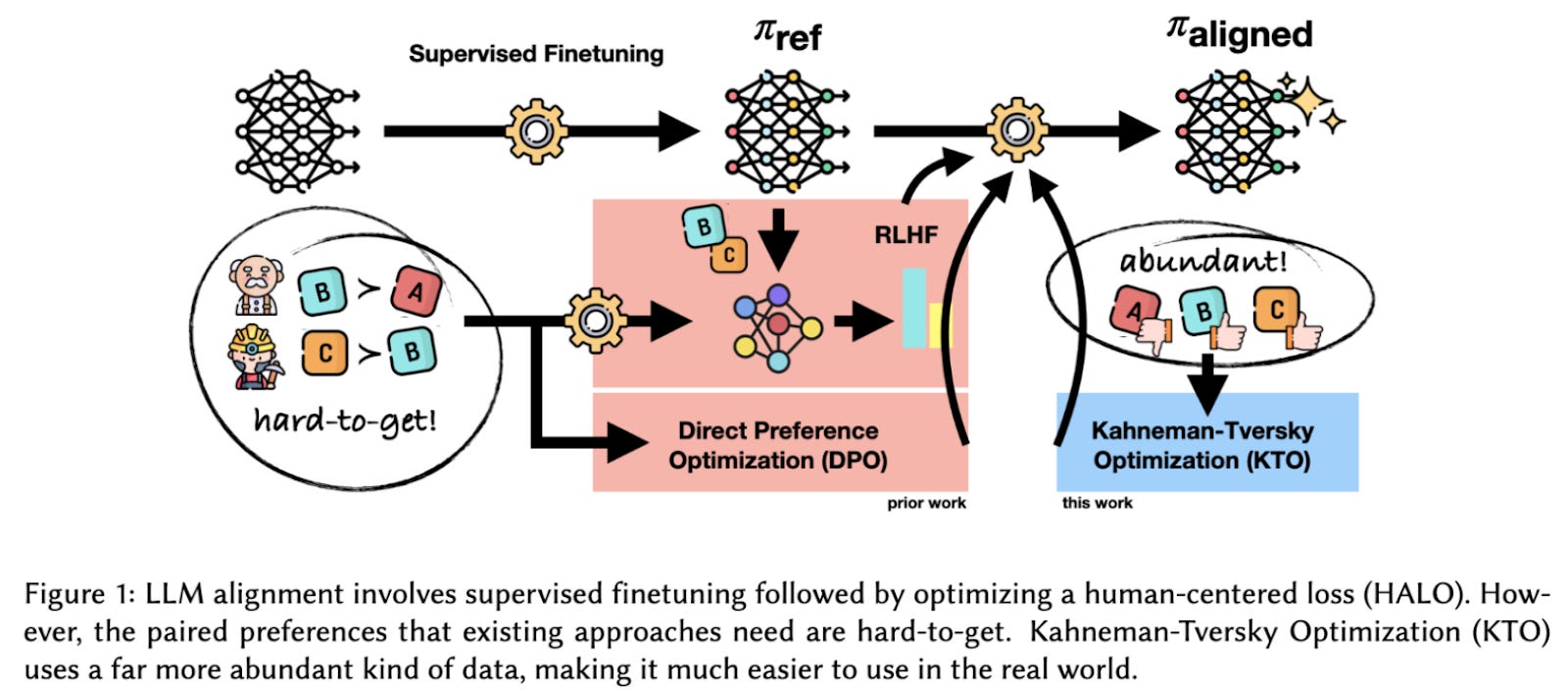
Their experiments show that KTO generally matches or beats DPO for models ranging from 1B-30B parameters. KTO also outperforms DPO when desirable data is progressively removed, since the KTO loss function can upweight examples that are desirable but rare. In the figure below, you see that even when ~90% of “desirable” responses are discarded, a KTO alignment outperforms DPO.
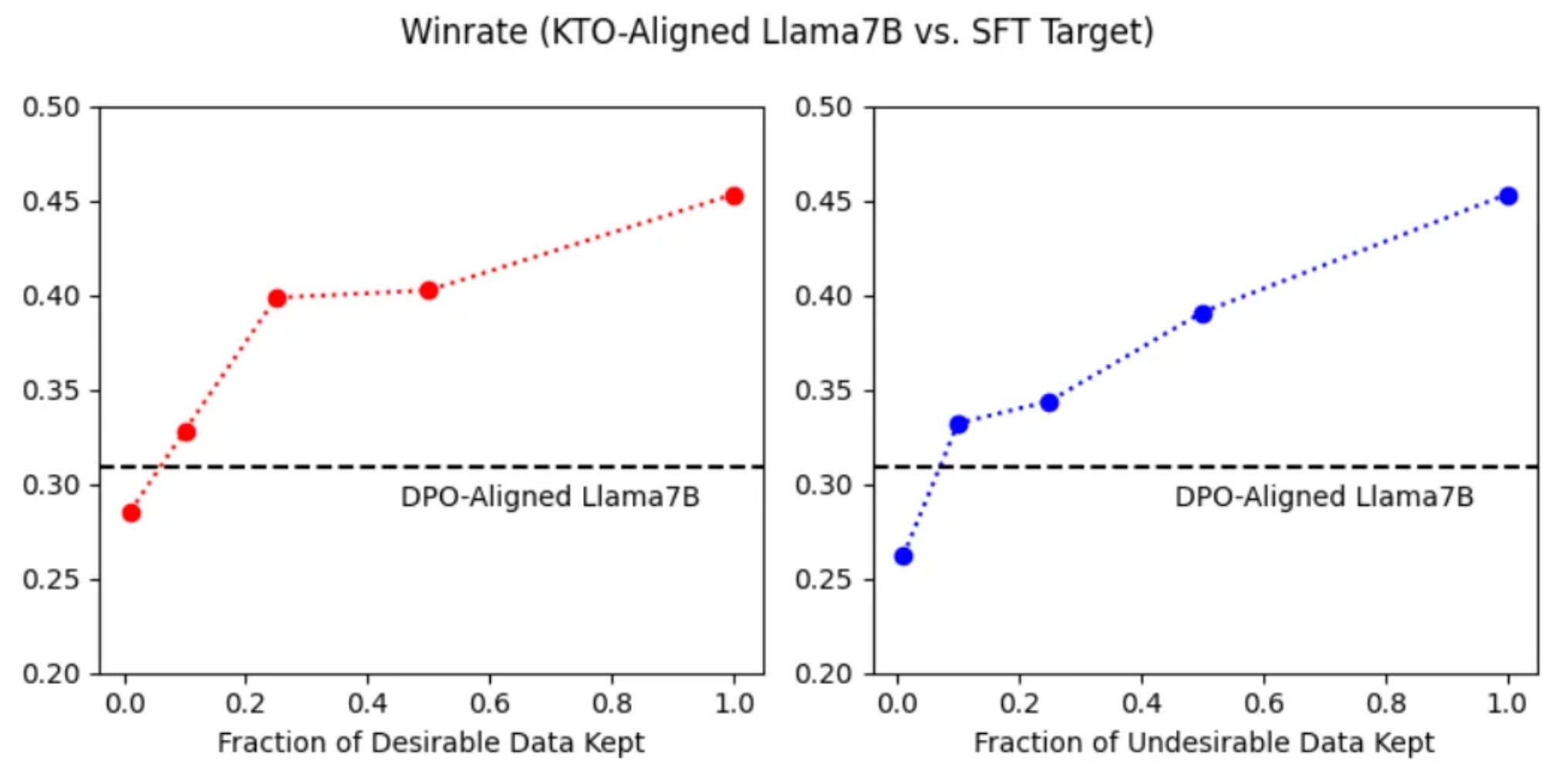
The development of new methods like DPO and KTO is a sign that we’re still learning which signals are important for training excellent models. It also underlines a common theme in machine learning — as a field, we often start with complex methods, then refine them down to the essentials, and finally conclude that “XYZ is all you need.”
The best models will come from product feedback loops
It’s important to reflect that, regardless of the technique, human preferences are a key component in training effective language models. Creating better models, no matter which method you choose, requires feedback from users.6
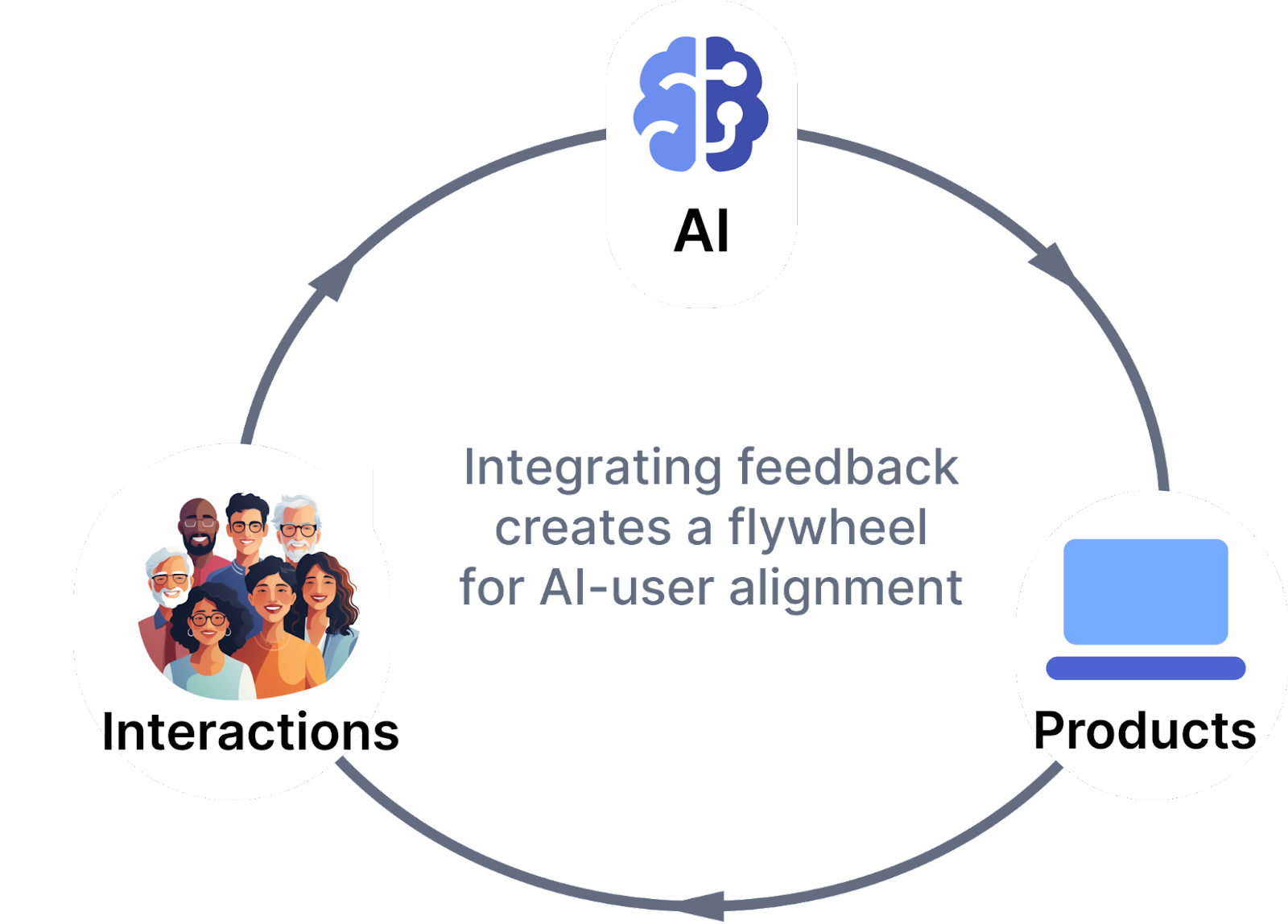
So what does that mean for the future? My prediction: the future of language models will be small, optimized models embedded in products, that are aligned by users through tight feedback loops.
Products incorporating language models can track interactions and gather feedback on model outputs to improve their responses. In this framework, we can give agency back to users, so they can more directly guide how language model systems behave.
In healthcare settings, this can be incredibly powerful. Here are some scenarios we’re excited about:
Accurate and succinct summarization: A model summarizes an encounter note or the transcript of a telemedicine call. The physician edits the summary and saves it. The system now knows that the physician prefers her edited version over the original. That (de-identified) summary can be used to fine-tune a reward model (PPO) or a language model directly (DPO, KTO).
More effective patient engagement: A message service sends reminders to patients to schedule a followup visit, using a slightly different message each time. Some patients immediately click a link to schedule, while others do not. The model can refine how it messages patients based on how effectively it led the patient to schedule.
Reliable coding: A coding assistant matches a physician's note to a set of codes for review and recommends them to an expert coder, who then adjusts the code set. Under the hood, the coding assistant learns to produce the edited set.
Better outreach for trials: A model embedded in an EMR detects that a patient is eligible for a clinical trial, and sends a note to their physician with information on the trial and how to discuss it with the patient. Feedback can be gathered directly from the physician, or by observing if the patient enrolls in the trial.
Safety and bias: A “red team” trains a reward model that aggressively penalizes harmful responses, like those with toxic language or that suggest actions that could lead to patient harm. This reward model monitors outputs in the EMR, and flags anomalous responses so they can be reviewed and addressed. Validated positive and negative responses are then used to improve production models. The team can also track model biases and how behavior changes over time, to protect patients.
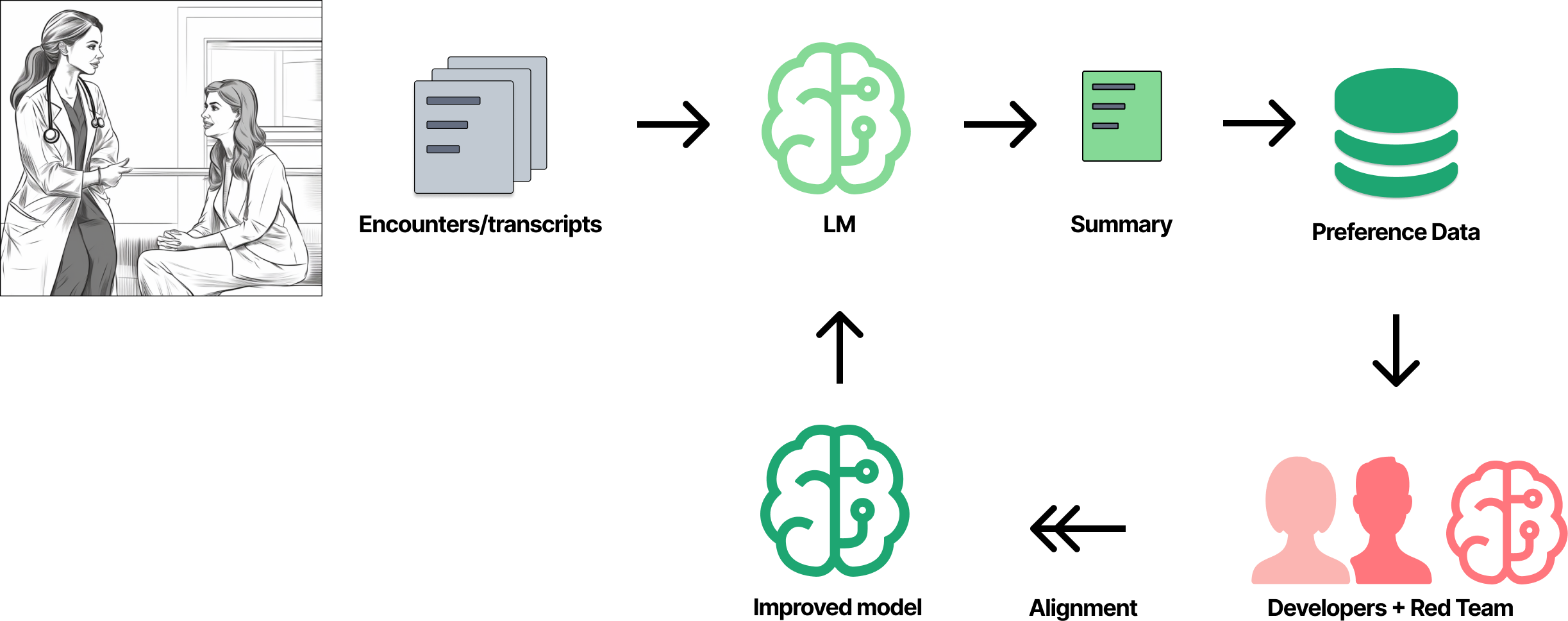
Machine learning is often a siloed process involving only developers and engineers. They might gather data or input from users and experts. But too often, especially in language modeling, data is taken from data labelers who don’t necessarily reflect the end user. Are comparison datasets generated by overseas labeling teams reflective of the preferences of doctors and nurses? I doubt it.
Instead, if done right, we can give agency back to care providers and patients, the end-users of healthcare systems. How effectively a software product’s AI/ML functions reflect their users’ preferences will make a huge difference in quality.
In healthcare, it could make a huge difference on patient outcomes.
Thanks to Stacey Rosenfeld and Will Manidis for their helpful feedback, and Paul Ledbetter for thoughtful discussions as I was writing this piece. Coming soon: we’ll take a look at the history of mixture-of-experts, another technique that has big implications for productizing models in healthcare. And we’ll discuss ways to measure and mitigate bias in production algorithms.
Glossary
Large Language Model (LLM): A type of neural network that processes and generates human-like text, usually with a transformer architecture. Large language models are trained on vast amounts of text data and are capable of understanding and producing text in natural language, making them useful for a variety of applications like conversation, translation, and content generation. Sometimes colloquially referred to as “AI.”
Alignment: Alignment refers to the process of ensuring that a model’s goals, decisions, and behaviors are aligned with human values and intentions. It is particularly important in the development of advanced AI systems to ensure that their actions are useful and not harmful.
Reinforcement Learning (RL): A type of machine learning where an agent learns to make decisions by performing actions in an environment to achieve goals. The agent receives rewards or penalties based on its actions, which guides its learning process. It can also exploit past experience or knowledge to make better decisions. RL is sometimes mentioned as RLHF when trained on data generated by people, and RLAIF when trained on data generated by other models (HF=human feedback; AIF = AI feedback).
Reward Model (RM): In reinforcement learning, a reward model is the mechanism that assigns rewards to the agent based on its actions and the state of the environment. The reward model helps guide the learning process by indicating which actions are beneficial towards achieving the desired objectives.
Exploration: When a model tries out different actions to discover their effects and rewards. It's about gathering information and learning more about the environment.
Exploitation: When a model uses its current knowledge to make decisions that maximize rewards. It can choose actions it knows are going to yield a high reward, based on its past experiences.
Proximal Policy Optimization (PPO): A reinforcement learning method that has been applied to language models. PPO is designed to balance the exploration and exploitation trade-off efficiently. It updates the policy in a way that doesn’t deviate too much from the previous policy, aiming to achieve stable and reliable training of the model.
Direct Preference Optimization (DPO): DPO is a method for teaching models to predict user preferences without an explicit reward modeling step. Instead, DPO directly optimizes the language model using binary cross-entropy loss. Its key innovation is that it shows preference learning can be framed as a supervised learning problem.
Kahneman-Tversky Optimization (KTO): DPO and PPO-based RL compare two responses and predict which one is preferred. Kahneman-Tversky Optimization (KTO) is a method where the model only needs to know if responses are desirable or undesirable, further simplifying how preferences are learned.
Comparison Data: A set of prompts and pairs of responses, one of which has been selected as the preferred response (usually by a person, sometimes by a model). These are used to train reward models (PPO) or fine-tune models directly (DPO).
T5 is a Text-To-Text Transfer Transformer.
This fine-tuning method is known as teacher-forcing, and can quickly guide sequence-to-sequence models to give correct outputs during training. Teacher-forcing is related to a now well-known approach called “instruction tuning,” where models are asked to perform a variety of tasks but are also given context and/or instructions. Instruction tuning emphasizes expanding the model's capabilities and flexibility in understanding and performing different tasks.
Technically, DPO and KTO are not reinforcement learning methods, since they optimize the policy directly using standard supervised learning, the reward model is implicit, and they lack other hallmarks of RL. However, they achieve a similar end goal (aligning a model to user preferences) through their loss functions, using essentially the same data.
Temperature is a parameter that controls the “entropy” of a model’s outputs. For example, consider a classification model that outputs a probability distribution over different classes. Higher temperature will "soften" this distribution, making the probabilities more uniform, and thus each class more evenly likely. Lower temperature will sharpen the distribution, making the largest probability larger and smaller probabilities smaller. For a language model, increasing temperature will increase the diversity of responses if you sample multiple times. Ask a low-temperature language model to pick a number between 1 and 100, and it will likely pick a number like “42” (because it’s read a lot of Douglas Adams) or “7” (because of its common association in literature with luck). Increasing the temperature will make it more likely that the model will pick a random number between 1 and 100.
Yup, the “Kahneman-Tversky” in KTO refer to the famous behavioral economists, Daniel Kahneman and Amos Tversky. Kahneman famously won the Nobel Prize in Economics in 2002 and published Thinking Fast and Slow in 2011, which adorns many a bookshelf. Tversky unfortunately passed away in 1996, but his contributions live on.
There have also been important advances in using “AI feedback” to improve models (see Anthropic’s work with Claude 1 and 2), but even the models giving feedback are built on knowledge only humans can provide. AI feedback methods are, in my opinion, more useful for bootstrapping or supplementing data for alignment than something we should aspire to replace people with.
 | A guest post by
|