

Large Language Models for Healthcare (Part 1)
An accessible intro to LLMs, how they work, and what makes them useful


👋 to 1181 awesome readers, including 154 of you who joined last week.
Today, we’re kicking off the first post in a series about large language models (LLMs), how we see them being used today in healthcare, and where we think they’re going to go.
Edit: Part 2 is also now up
“Gaurav beta, do you know ChatGPT?”
This is not a question I expected to hear from my dad, the kind of parent who is generally proud of his kids without really knowing what they do.
“Yeah, I’ve played with it … a bit.”
My dad’s an oral surgeon who loves software. He bought our first PC back when floppy disks still flopped, complete with a dot-matrix printer and a whopping 33kb of memory (we mostly used it to play Carmen Sandiego). In the 90s, he digitized his practice and has used electronic records ever since.
Even so, he approached new technology like a child at a magic show. He’d marvel at things like WiFi and ask me how it worked. I’d do some research and relay what I found.
Try as I might, I could never explain things well enough to satisfy his curiosity. He didn’t want a Google search, he wanted intuition.
“Uh-huh, ok. So how does it work?”
Welp.
A No-Math Introduction to Large Language Models
Imagine you want to teach a “robot” to talk like a person.
Before large language models, we thought the best approach was to craft a set of rules that explain how people talk. By following those rules, a robot could replicate speech.
It turns out that robots don’t need rules. They learn better if you give them 1) a lot of text and 2) a simple task to perform.
One approach you can take is to give the robot the first sentence of a paragraph and ask it to predict the words that come next (a task unsurprisingly called “Next Sentence Prediction”).
Another popular approach is to give it a sentence with some words missing, and have it try to fill in the blanks (which is called “Masked Language Modeling”).
The process of having models learn from large volumes of text using simple tasks is called pre-training. And it’s turned out to be incredibly powerful. Models that pre-train are capable of learning a ton of nuance about language. They even learn implicit rules, like how context can change the meaning of certain words, which are often very hard to describe as rules.
Now let’s say you don’t want the model to just predict words or fill in blanks. You want it to do something specific, like learning more about a complex topic or answering questions accurately.
Good news! Pre-training has given your robot a very strong baseline to learn new tasks.
We can do a few things to make it good at specific things.
One, we can have it learn more with relevant text. (Want it to be better at finance? Give it a ton of Bloomberg data. Esoteric Simpsons trivia? I’ve got just the website for you.) We can also teach it to do new by giving it new data or modifying its architecture. We can also “align” it to behave in a certain way with some feedback.
Amazingly, you don’t need a lot of data to have a pre-trained model learn something new, which is why we call it fine-tuning.
Some very large models, like GPT-4, don’t need to be fine-tuned to perform well on specific tasks. They’re capable of in-context learning; where they infer what you want them to do from what you say.
For example, you can ask GPT-4 to answer a question as an expert, or as a fool. You can ask it to write a poem, even from a specific person’s point of view:

How does this work? Imagine a chef who specializes in Italian dishes. One day, a customer asks for a pasta dish they’ve never made before. With a brief description of the dish and some key ingredients, the chef can make it. They probably could make other, non-Italian noodle dishes without much effort too. There is a limit though — don’t ask them to make a rocket ship, it's too far beyond their experience.
Making Text Computable, or Why Robots Don’t Need Rules
How are models able to learn from text or images?
Well, computers are just rocks we tricked into doing math with electricity. So if you want a computer to work with something like a picture or a book, you need to turn it into numbers.

To turn words into numbers, we could do something simple: let’s give each word in the dictionary a unique number (apple= 1, banana= 2, cats=3, and so on).
Sentences are just sequences of numbers (Cats like apples=[3, 15, 1]). To predict what comes after “Cats like apples”, our LLM needs to learn to predict the next number in the sequence.
The numbers we’re choosing are arbitrary, but what if we choose them so they are more useful? Can the numbers reflect the meaning of each word or its relationships to other words?
Words are, in fact, not represented arbitrarily by LLMs; instead, LLMs use what we call word embeddings; Each word is a vector or a list of numbers. Importantly, similar words have similar embeddings, and the relationships between words can be captured mathematically.
One way to think about word embeddings is as coordinates on a map. The map is every possible word or phrase the model encounters. A map of a city is a collection of coordinates that describe what’s in that city and how to navigate it. Similarly, word embeddings are the coordinates on a map of language; Similar words used in similar contexts appear closer to each other in the “map.”

Models can even generate embeddings of sentences, paragraphs, and documents. Similar text will have similar embeddings. Using embeddings to find similar text is a technique called vector search.
You can even represent people as embeddings. Imagine a database of patients, except each patient is represented as a vector averaged across all their medical records. If you wanted to find similar patients, find similar vectors. Want to find patients who might match a clinical trial? Encode the trial inclusion criteria as a vector, and then find similar patient vectors. Having trouble diagnosing a patient? Look at the outcomes for patients with similar vectors. Complex information mining can be done with some high-school-level math.
As LLMs learn, word embeddings can be updated to capture how the words are used in specific contexts. This is one reason why models which are fine-tuned in specific domains outperform general models — they learn to understand the words better in that specific context.
How To Train Your Model
How do we make great LLMs?
There are four levers we can pull: architecture, model size, data, and compute.
By architecture, I mostly mean the kind of neural network you use. In 2017, researchers at Google proposed a new kind of neural network, the Transformer, which uses a mechanism called “attention” to help it to focus on the most important words while also considering the overall context. It's similar to how you might pay more attention to the most important or relevant parts of a conversation. The transformer completely changed the landscape of language modeling, and no other architecture has been able to compete.

Once the field converged on transformers, model size was the next most popular lever to pull. How big can or should we make these models?
In January 2020, OpenAI published a paper called “Scaling Laws for Neural Language Models” which asked an important question about designing LLMs. Let’s say you have a fixed amount of compute resources (GPUs, time) and want to build a model. For a fixed compute budget, as you increase the model’s size you must train it on fewer data.
What’s the best tradeoff between model size and data, to get the most bang for your computational buck? And, when we do get more resources, should you focus on making larger models or on getting more data?

OpenAI’s findings suggested that increasing the model’s size was more important than adding more data. As your compute budget increases by 10X, model size should increase by 5X while data need only double. These scales compound, so with 1000X more compute, models should get ~125X bigger while data only need to increase by ~8X.
Since then, there has been an explosion in massive models, while gains in dataset size were more modest.

Then comes DeepMind in 2022 with a paper called "Training Compute-Optimal Large Language Models." Given the same compute budget, DeepMind found that data was the most critical lever.
They created Chinchilla, a 70B parameter model trained on 1.4T tokens (words and word fragments). They then compared it to Gopher, a 280B parameter model trained on 300B tokens.
It turns out Chinchilla, at ¼ the size but trained on ~5X more data, matched or bested Gopher on 93% of all tasks.
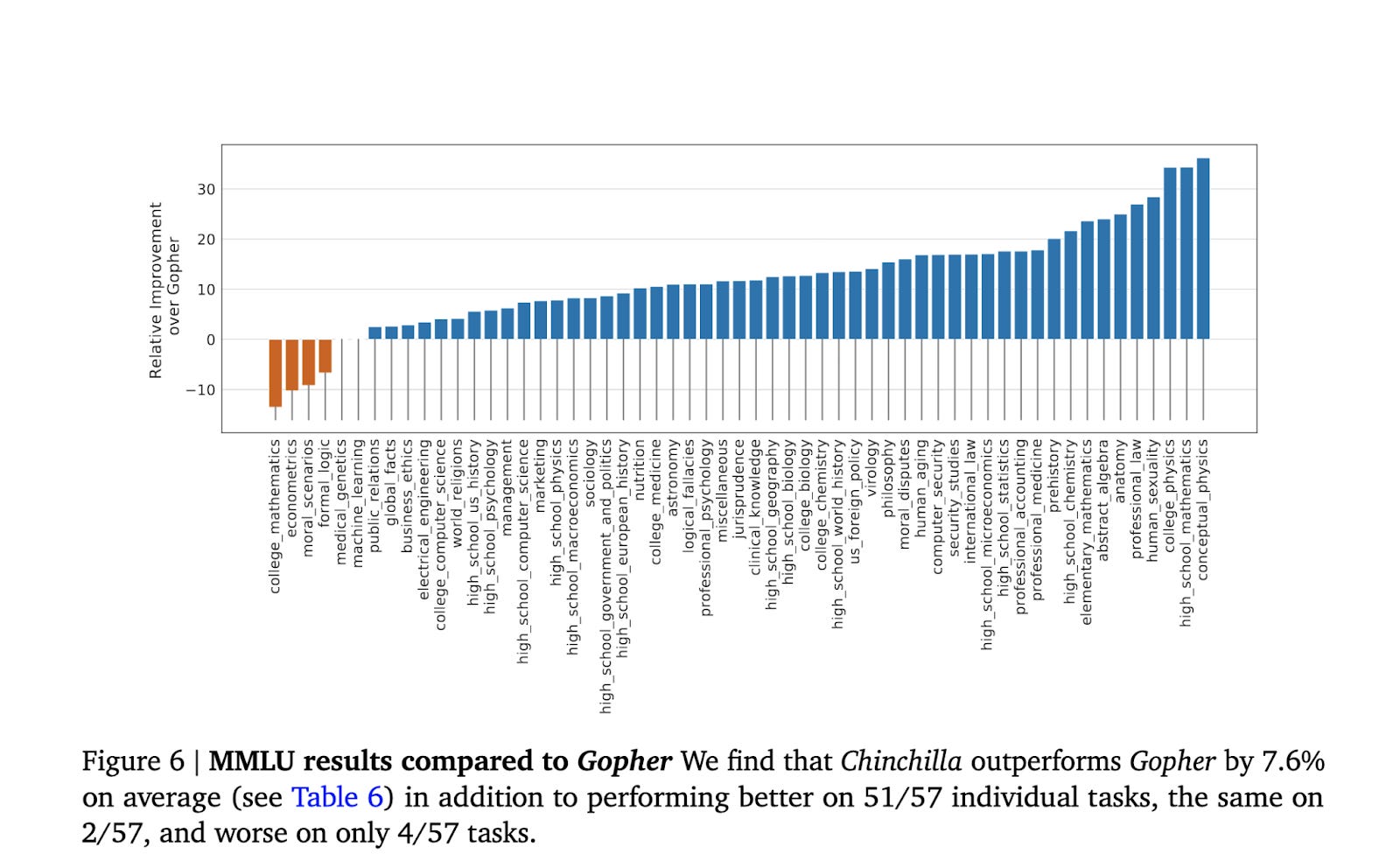
These findings had significant consequences. As LLM developers got access to more compute, DeepMind suggested it was better to scale up your data, not lean into creating massive models. The old machine learning adage “the more data, the better” rings true once again.
In the last year, we’ve seen a volley of parameter-efficient models hitting the scene with performance on par or exceeding GPT-3, including Meta’s LLaMa, Stanford’s Alpaca, and Databricks’ Dolly.
Parameter-efficient LLMs have profound advantages. Because they’re smaller, they’re much easier to train, can train on more data easily, and are easier to use for inference or prediction. They can also be more easily fine-tuned for special tasks or to perform better in specific domains.
Though massive LLMs like ChatGPT and GPT-4 have gotten a lot of buzz in recent months, I would argue that we now live in the age of parameter-efficient LLMs, which will become increasingly democratized and specialized.

(For a more detailed analysis of scaling laws, check out this excellent post from LessWrong.)
Bring on the Specialty LLMs
Data matters. Models trained on internet text may struggle in specialized domains because they haven’t seen enough relevant text to form a good representation of domain-specific concepts.
We can help LLMs improve on specialized domains, like healthcare, in a few ways:
Pre-training with medical text and medically-relevant tasks
Fine-tuning pre-trained models on medically-relevant text and tasks
Aligning an existing model to be more reliable in a medical setting
Monitoring real-world use, e.g. for safety and efficacy
Adapting or training LLMs for healthcare intelligently is going to require a lot of data, thoughtful data design, and experts in the loop. Healthcare has high barriers to entry as an industry so getting expertise to make excellent, general-purpose healthcare LLMs is a challenge.
But enormous possibilities will open up as LLMs get better at healthcare and healthcare ops.
In Part 2: I’ll make the bull case for LLMs in healthcare and discuss use cases that LLMs can enable today.
(Meanwhile, I’ll be sending this post to my dad.)
Thanks for reading,
Gaurav 🌊
A warm thank you to Alda Cami and Raunaq Malhotra for their feedback. 🙏🏽